All about Elastic Search Part I
20 Jul 2017
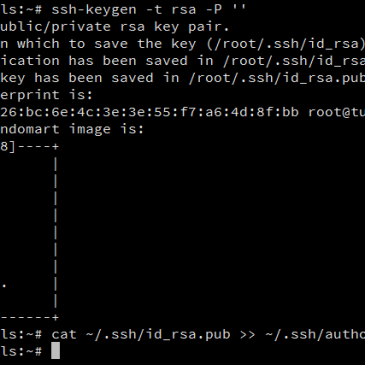
Search is a common building block for applications. Whether we are searching Wikipedia or our log files, the behaviour is similar. A query is entered and the most relevant documents are returned. The core data structure for search is an inverted index. Elasticsearch is scalable, resilient search tool that shards and replicates a search index. … More All about Elastic Search Part I